

Deep Learning vs. Traditional Machine Learning: A Comparison
Over the past decade, deep learning has emerged as a dominant force in the field of artificial intelligence. But how exactly does deep learning differ from more traditional machine learning approaches? This article provides an in-depth look at the key differences, real-world applications, and reasons why deep learning is gaining so much traction.
A Quick Primer on Machine Learning
Before diving into deep learning specifics, let’s step back and define what machine learning is at its core.
Machine learning refers to algorithms that have the ability to “learn” from data, identifying patterns and making decisions or predictions without being explicitly programmed to do so. The algorithms iteratively learn from data, improving their analysis and decision-making over time.
Within the field of machine learning, there are three primary approaches:
- Supervised learning: The algorithm is trained using labeled example data, mapping input data to expected outputs. Common tasks include classification and regression.
- Unsupervised learning: The algorithm must find patterns in unlabeled, uncategorized data. Clustering is a key unsupervised task.
- Reinforcement learning: The algorithm determines which actions yield higher rewards through trial-and-error interactions with a dynamic environment.
Deep learning and more traditional machine learning both utilize these fundamental approaches. Yet deep learning models developed by a deep learning development company can yield far more accurate results thanks to architectural differences, which we will explore in more detail later.
Understanding Deep Neural Networks
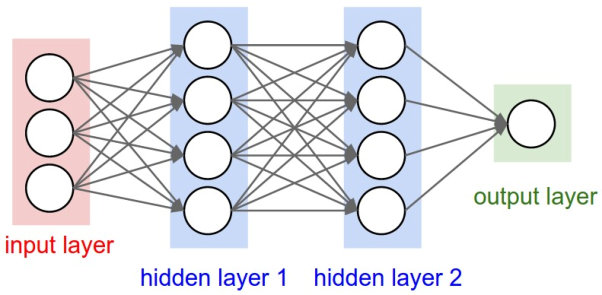
The “deep” in deep learning refers to deep neural networks: artificial neural networks with multiple layers between the input and output layers. Here’s a quick example:
Source
Deep Neural Network Layers
As shown above, these networks have an input layer to receive data, an output layer that makes a prediction, and, critically, multiple hidden layers in between that perform computations to glean insights from the data. Each layer consists of neurons that process and pass data onto the next layer.
The term “deep” really refers to the depth of these networks’ architectures in terms of layers and parameters. Deep learning models can have hundreds of layers as opposed to just a few, which significantly expands their learning capacity.
In contrast, traditional machine learning algorithms like logistic regression or random forests do not operate through deep neural networks. Some of these differences lead to huge performance gaps in certain applications, which brings us to our next key topic.
Real-World Performance and Applications
Deep learning thrives in complex real-world environments with massive datasets, outperforming other approaches. It has propelled innovation in fields as diverse as computer vision, speech recognition, and game-playing.
Consider the jumping accuracy on the ImageNet image classification benchmark, which contains over 14 million hand-labeled images spread across 20,000 categories. In 2011, the best algorithms achieved just under 26% accuracy. With deep convolutional neural networks arriving in 2012, accuracy jumped to 83% by 2016. Traditional approaches simply could not make such gains given the task complexity and volume of data.
Many real-world application examples stem from computer vision based on deep learning’s pattern recognition capabilities:
- Identifying faces in images and video feeds
- Classifying content across social media platforms
- Guiding self-driving vehicles
- Spotting cancerous tumors in medical scans
- Tracking human poses and movements
Deep learning also excels at natural language processing (NLP) applications with large text corpora:
- Machine translation across languages
- Text generation mimicking human writing
- Interpreting spoken languages
- Suggesting email reply content
Even defeating human champions in complex games like Go requires deep neural networks’ high-dimensional pattern mapping. And in an organizational context, deep learning can significantly augment areas like analytics, forecasting, and recommendation engines.
Traditional Machine Learning Strengths
While deep neural networks offer breakthrough capabilities, traditional machine learning approaches have some advantages that make them preferable for certain use cases:
- Simplicity and interpretability: Algorithms like decision trees, logistic regression, and linear models are much simpler. Their logic is more easily interpreted, especially for less technical users. Deep learning systems remain complex black boxes by comparison.
- Less data required: Deep learning models have so many parameters that they require massive training datasets, which traditional ML does not. In data-scarce environments, going the traditional route may make more sense.
- Speed and efficiency: Training deep learning models can take hours or days. Faster fitting and prediction are achieved by much simpler algorithms. However, this difference really matters for applications where real-time performance is critical.
- Overfitting avoidance: Traditional ML models are more prone to avoid overfitting training data with fewer parameters. Without carefully regularized and cross-validated, deep learning models can easily overfit.
In the end, every application should be evaluated separately. But interpretability, speed, and overfitting avoidance give traditional techniques enduring relevance.
Computer Vision Applications
Today, deep learning is one of the most popular domains to apply deep learning to, and computer vision is probably the most popular domain. But more traditional machine learning approaches still have relevance for some use cases based on certain tradeoffs:
- Image classification: We find that deep convolutional neural networks (CNNs) outperform other algorithms by a large margin in the task of classifying images into different categories based on the presented visual features. However, for cases with fewer data or less complicated classification problems, simpler models like SVMs might be better suited.
- Object detection: Faster R-CNN is a deep learning object detection model that can find multiple objects in an image and draw bounding boxes around them. However, traditional algorithms are sometimes enough for small, simple, or predictable objects, and they require less computing power to detect them.
- Image segmentation: Pixel-level segmentation is a strength of deep learning U-Net models that split an image into pieces according to classification. However, for simple use cases where there might be little background noise, one might be able to get by by using basic color thresholding or edge detection from classical CV techniques.
- Anomaly detection: If you train deep models on what normal images look like, they can effectively detect anomalies. However, directly applying traditional computer vision techniques to find anomalous edges, shapes, textures etc., can supplement deep learning.
The takeaway is that while deep learning has become the dominant approach, especially for complex vision tasks, traditional CV still powers simpler use cases. The two approaches actually pair together nicely in ensembles or as steps within a pipeline.
Natural Language Processing Applications
Natural language processing (NLP) has become a hot topic since the advent of deep learning and huge language models such as BERT, GPT3, and PaLM. However, traditional techniques maintain relevance for multiple reasons:
- Text classification: Multi-class document classification using deep neural networks is vastly better than the kinds of algorithms like Naïve Bayes. However, linear models and random forests are good for simple single-label classification tasks.
- Sentiment analysis: More accurate sentiment nuances are detected by complex LSTM and CNN models. Nevertheless, for basic binary positive/negative classification, SVMs, logistic regression and other traditional models are faster and simpler.
- Topic modeling: ProdLDA, for example, is a deep learning topic model that overcomes the limitations of coherence and interpretability. Nevertheless, traditional latent Dirichlet allocation (LDA) is still used to discover topics.
- Language generation: Deep learning models can generate extremely human-like text for things like chatbots and can be massive. In the case of tightly scoped use cases, however, traditional template-based generation is sufficient.
Combining traditional techniques and deep neural networks within NLP pipelines, as in computer vision, allows us to exploit the strengths of each approach. And simpler traditional models will continue serving key language processing needs in the future.
Key Takeaways and Future Outlook
This thorough comparison only scratches the surface of such a complex topic. Here are the key differences and takeaways to remember:
- Deep learning relies on deep neural networks with many layers, and breakthroughs are achieved when massive datasets meet high dimensional pattern recognition challenges.
- With simple neural architectures, things become more complex: for instance, random forests and linear/logistic regressions are simpler algorithms covered by traditional machine learning.
- Its high-performance ceiling enables deep learning to excel in complex real-world tasks such as computer vision, NLP, recommendation systems etc.
- However, traditional machine learning still has an edge in terms of model simplicity, speed, data efficiency, and overfitting avoidance, which endures.
- In most problem domains, the most successful approach combines traditional techniques and deep learning models in pipelines to magnify their respective strengths.
The future for deep learning is bright as it expands its reach, and traditional machine learning will continue to perform tasks that require trusted transparency, speed, and efficiency that are appropriate for the constraints. The next generation of AI will be orchestrated and will drive the complementary systems.
***
Alice Larionova









